

Multi input step
The multi input step (MIS) is a new feature introduced in Integray to enhance the flexibility and efficiency of data integration workflows.
The multi input step facilitates branch synchronization and allows you to receive multiple inputs within their integration processes. By incorporating this functionality, you can streamline complex integration tasks and achieve improved scalability, parallel processing, and system responsiveness.
This documentation outlines the main features, benefits, and usage guidelines of Multi input step.
Key features
-
Parallel Data Processing: Integrations can be executed parallelly, leading to enhanced scalability and reduced processing times. This is particularly advantageous when waiting for multiple independent external dependencies or services.
-
Easy Sync of Integration Branches: You can effortlessly bifurcate integrations based on unique criteria, such as connectors or schemas, and seamlessly merge divergent branches back into a unified logic flow. This results in simplified and more understandable workflows.
-
Endpoint Efficiency Enhancement: You can now easily define a single output source for both simple endpoint setups and complex branching integrations, streamlining the process and boosting overall efficiency
-
Simplified Aggregations and Merging: Complex aggregation tasks, such as appending additional details to data collections, can be achieved seamlessly in a single step, eliminating the need for additional service calls or temporary storage, thereby reducing maintenance efforts and error susceptibility.
-
Show data dependencies toggle button: A straightforward display of data flow between individual steps in the task. With the addition of a new button, the connections between each step are visualized.


Usage guidelines
Connector Compatibility
Multi input step is currently supported by JS Mapper version 3.3.0.
-
Input Handling: With JS Mapper version 3.3.0. you can designate secondary inputs alongside the primary input for a step. Secondary inputs are labeled as InputData2, InputData3, and so forth, based on selection order.
-
Execution Conditions: The step is processed on time in the queue after processing all secondary inputs. Valid data will usually be reached, while unavailable data will be treated as null.
-
Branch Synchronization: The step waits for all incoming branches to reach synchronization before execution. If any branch stalls before reaching synchronization, the task will be suspended until all branches converge.
-
Input Filtering: Filtering conditions applied to inputs are respected during step execution.
Adding secondary inputs
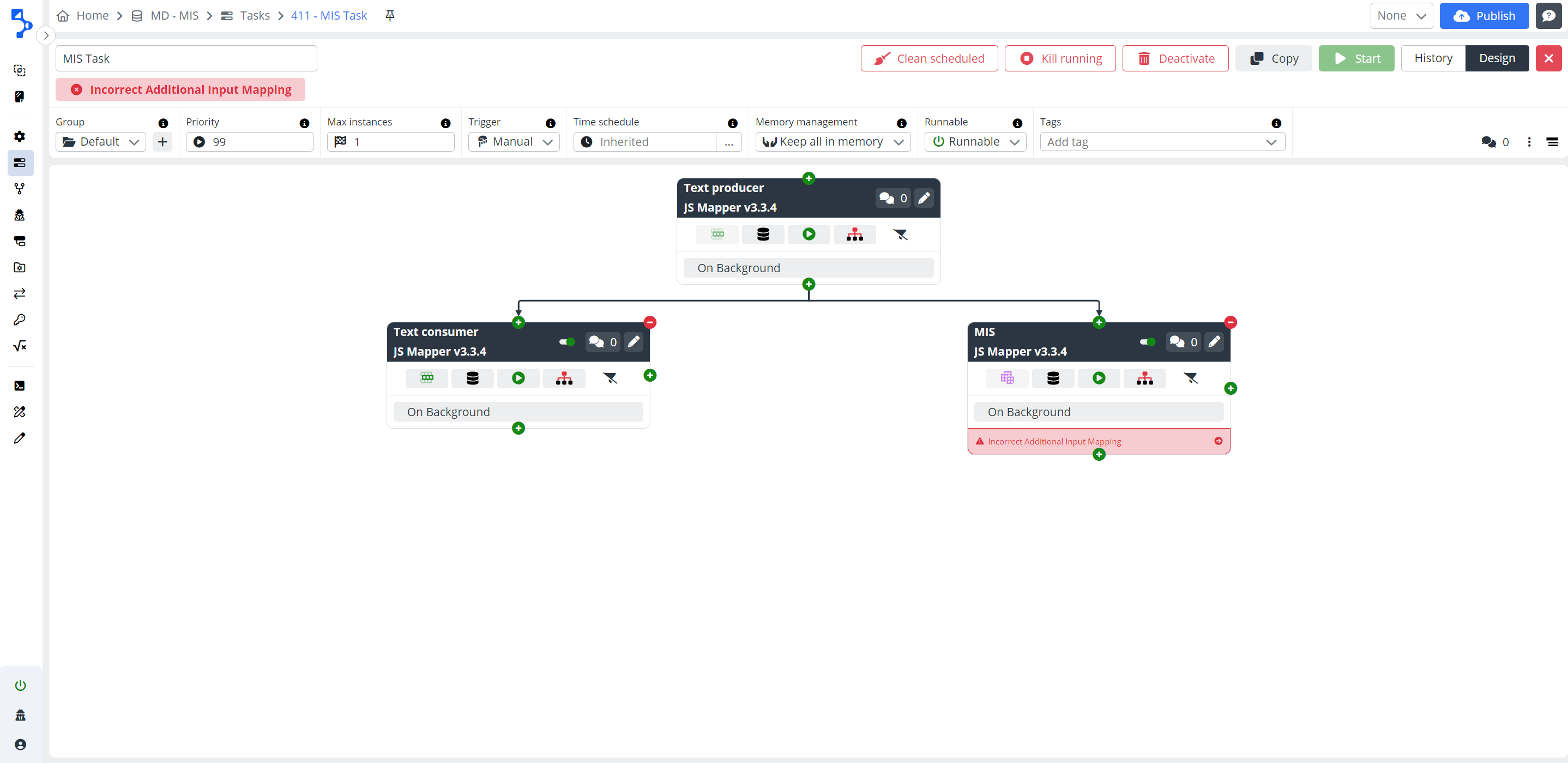
Secondary inputs are added using the + button in the configuration of the step intended to be used as a Multi input step.

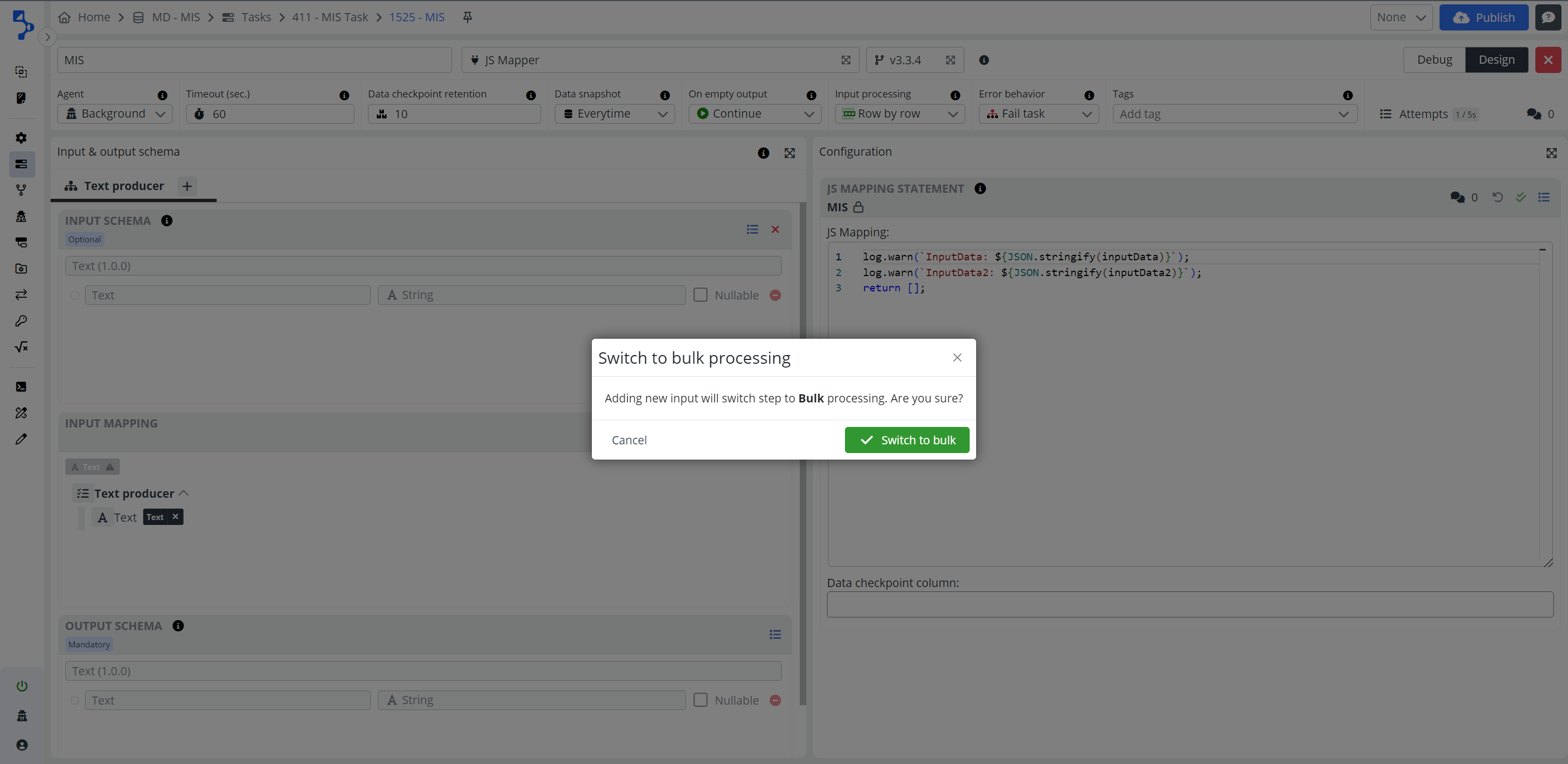
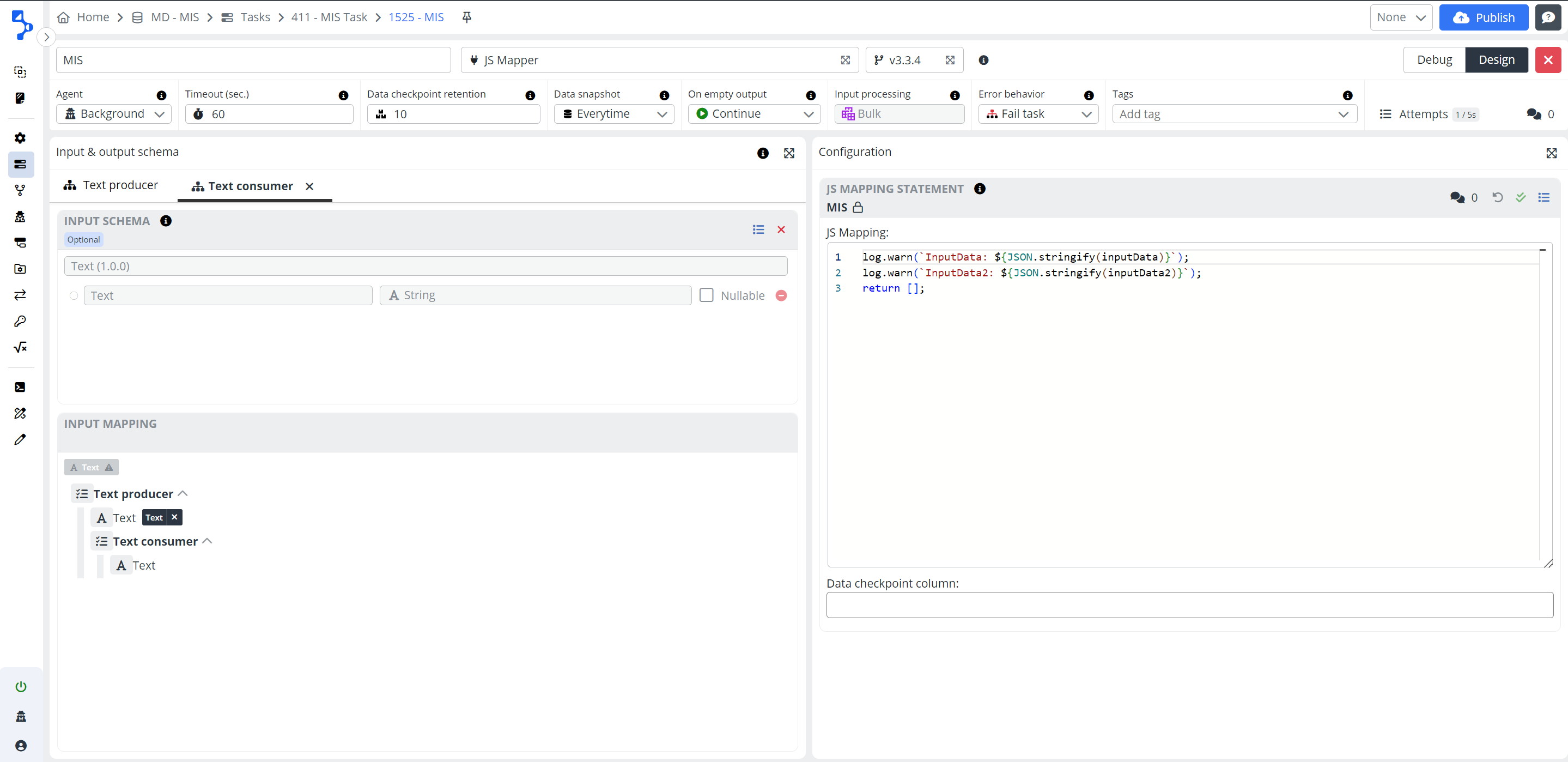
Bulk Processing
A step with a Multi input step will always be processed in bulk. When adding secondary inputs, you will be notified that the step will switch to bulk processing mode. Processing row by row isn't feasible due to multiple data collections, which can't be sensibly presented to users for individual handling. Therefore, all data will be received at once, with any necessary iteration managed internally.

Temporarily disabled steps / branches
Temporary deactivation of correctly configured steps/branches does not affect executability to ensure that tasks remain runnable.
You will only discover this when inspecting the settings of the Multi input step, where you may encounter an orange exclamation mark and the message: "Source step is temporarily disabled".

Upon publication and execution, in the History view, data from the disabled step will appear as "null".

However, if the mapping is adjusted to fetch data from a step preceding the disabled one, the data will still be retrieved even if the disabled step did not run.
Warning
In cases where the Multi input step lacks schema on secondary input, this condition will reflect in Task executability, rendering the task not executable.
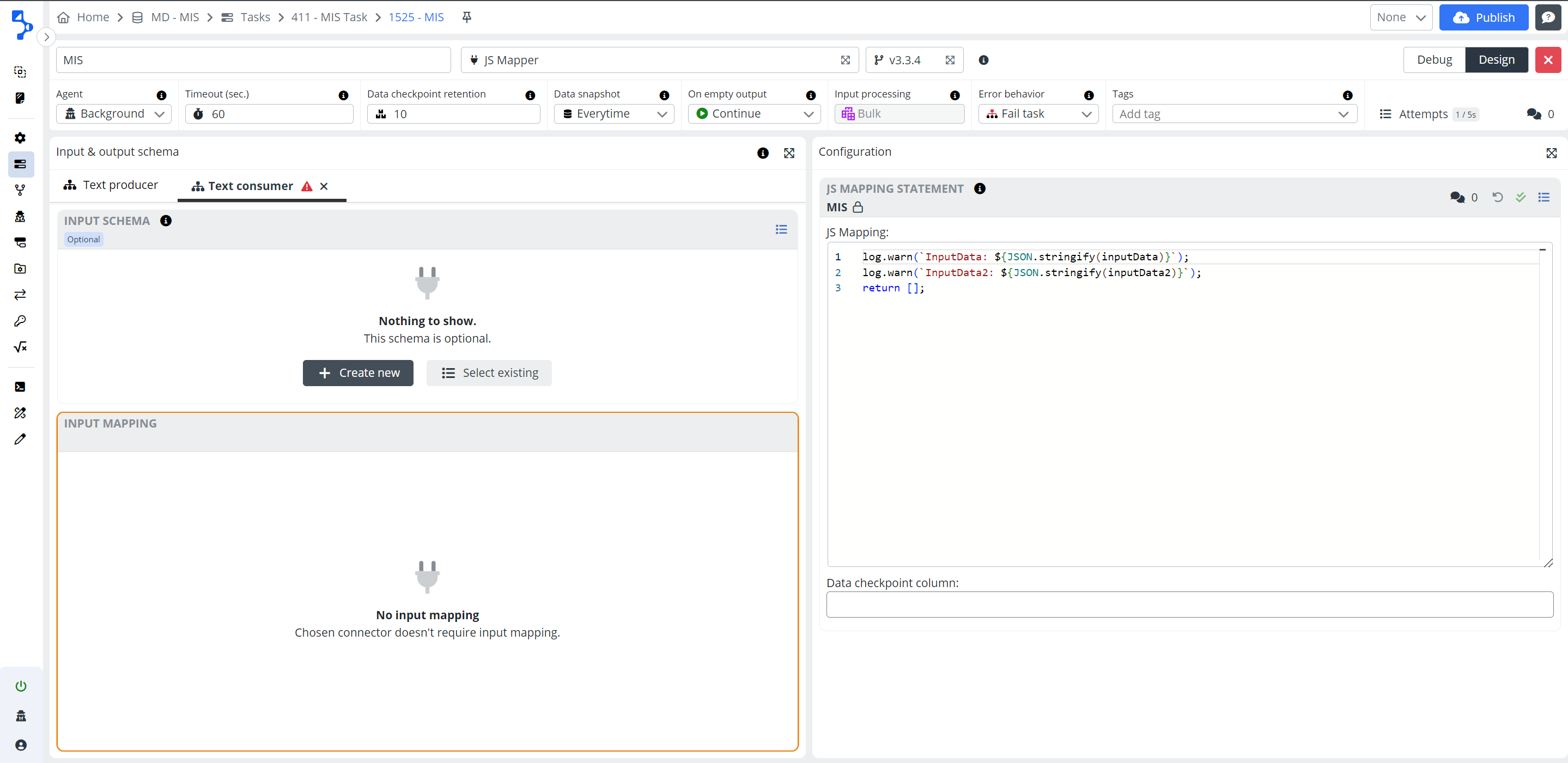
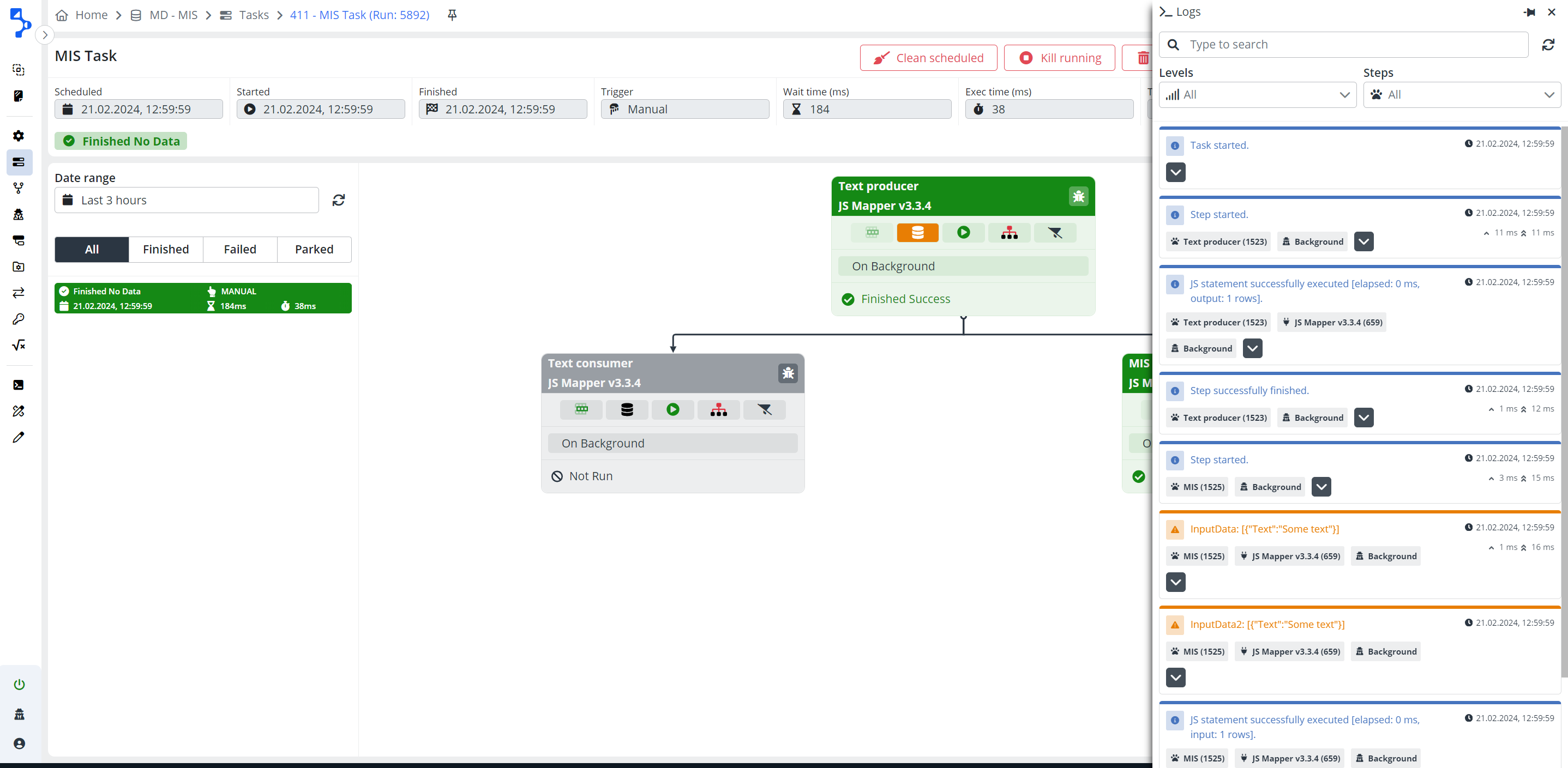
Null primary data
Info
- InputData receives a "null" value: In cases where data is consumed from a branch or step that is temporarily disabled, has failed, or is in a "Not run" state, the multi input step's input data will receive a value of "null." This applies to both primary and secondary inputs
- InputData receives an "empty" ([]) value: If data may have been received, but the input does not meet the filtering criteria, or the data source did not produce any records, resulting in an empty array ([]).
Warning
Previously, when the JS Mapper received "null" input, it would always insert an empty array ([]). However, with the upgrade of connectors supporting Multi input feature, JS Mapper version 3.3.0, the connector will provide "null" input data in this scenario.
Input and output limitations
Info
-
The Multi input step can have multiple inputs but only a single output.
-
It can only accept inputs from steps above it in the same branch but cannot accept input from its own branch from steps that follow Multi input step. It can certainly accept inputs from other branches.
This configuration variant involves expanding the input while ensuring that other aspects adhere to standard steps, such as "On empty output" and "Error Behavior." Described in Task steps.
Handling failed or not run inputs.
Primary and secondary inputs from failed or not run steps are "null" and not an empty array.
Conclusion
The Multi input step feature empowers you to orchestrate intricate integration workflows with greater efficiency and flexibility. By facilitating parallel processing, seamless branch synchronization, and simplified data handling, this feature enhances the overall productivity and reliability of integration tasks within the Integray.